Now Reading: Deep Research AI Agents
-
01
Deep Research AI Agents
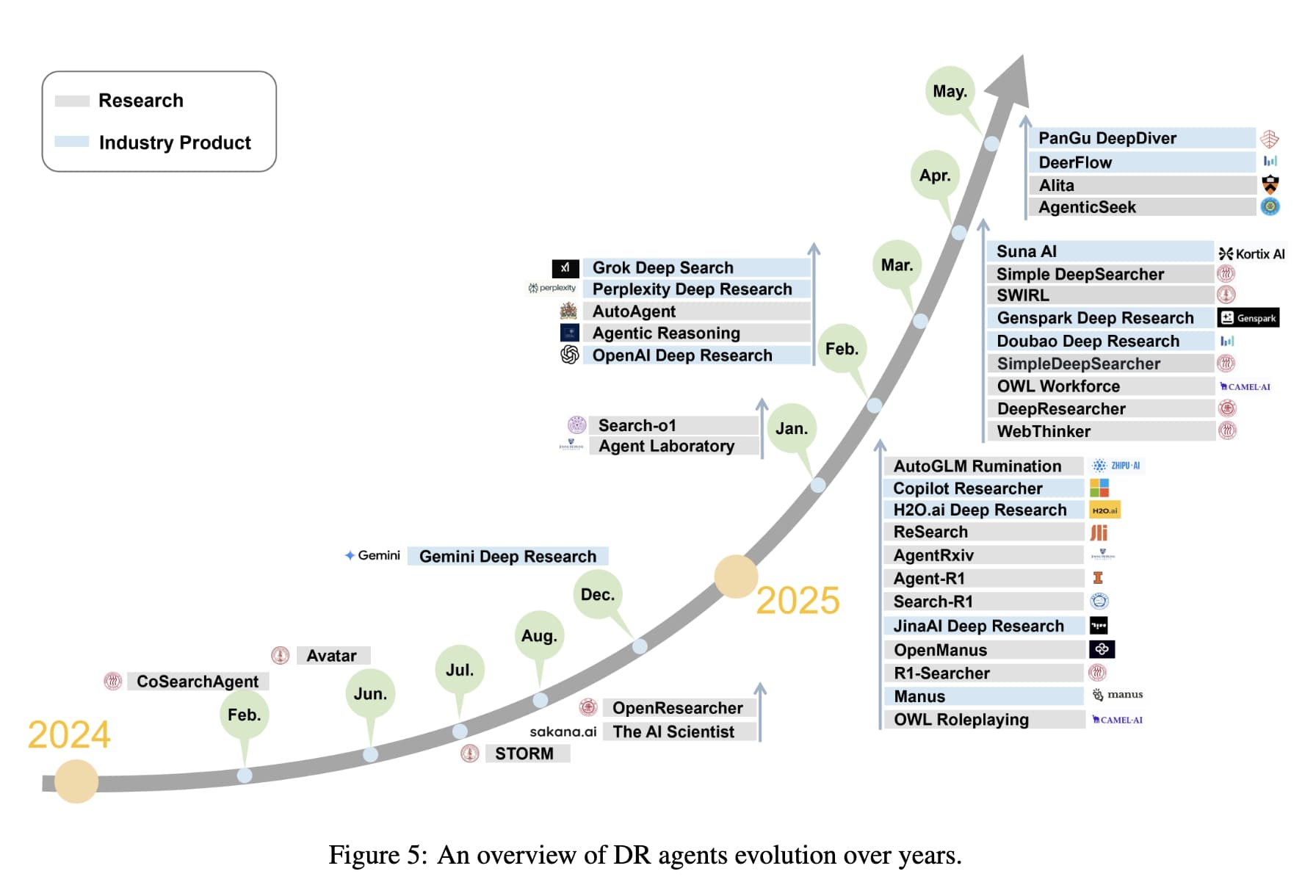
They begin by reviewing information acquisition strategies, contrasting API-based retrieval methods with browser-based exploration. We then examine modular tool-use frameworks, including code execution, multimodal input processing, and the integration of Model Context Protocols (MCPs) to support extensibility and ecosystem development. To systematize existing approaches, they propose a taxonomy that differentiates between static and dynamic workflows, and they classify agent architectures based on planning strategies and agent composition, including single-agent and multi-agent configurations.
They provide a critical evaluation of current benchmarks, highlighting key limitations such as restricted access to external knowledge, sequential execution inefficiencies, and misalignment between evaluation metrics and the practical objectives of DR agents. Finally, they outline open challenges and promising directions for future research.

API-based retrieval is a fast, efficient, structured, and scalable method that allows DR agents to access external knowledge sources with relatively less time and computational cost. For instance, Gemini DR leverages multi-source interfaces, most notably the Google Search API and the arXiv API, to perform large-scale retrieval across hundreds to thousands of web pages, thereby significantly expanding its information coverage. Grok DeepSearch claims to ensure both the freshness and depth of its knowledge base by maintaining a continuous index via news-outlet feeds, the Wikipedia API, and X’s native interface, and by activating a query-driven agent on demand to generate targeted sub-queries and fetch relevant pages in real time.
Browser-based retrieval provides DR agents with dynamic, flexible, and interactive access to multimodal and unstructured web content through simulated human-like browser interactions. For example, Manus AI’s browsing agent operates a sandboxed Chromium instance for each research session, programmatically opening new tabs, issuing search queries, clicking through result links, scrolling pages until content thresholds are met, filling out form elements when necessary, executing in-page JavaScript to reveal lazily loaded sections, and downloading files or PDFs for local analysis. Although OpenAI DR, Grok DeepSearch, and Gemini 2.5 DR do not publicly disclose the implementation details of their browsing capabilities, their ability to handle interactive widgets, dynamically rendered content, and multi-step navigation strongly suggests that they too employ comparable headless-browser frameworks behind the scenes.
Tool Use: Empowering Agents with Extended Functionalities
To expand DR agents’ capacity to interact with external environments in complex research tasks, specifically by actively invoking and handling diverse tools and data sources, various DR agents have introduced three core tool modules:
code interpreters,
data analytics,
multimodal processing, along with the Model Context Protocol.
Code Interpreter. The code interpreter capability enables DR agents to execute scripts during inference, allowing them to perform data processing, algorithm verification and model simulation. Most DR agents, except CoSearchAgent, embed a script execution environment. They typically rely on Python utilities such as Aider and Java utilities to orchestrate dynamic scripting, conduct literature-driven analysis and carry out real-time computational reasoning.
Data Analytics. By integrating data analytics modules, DR agents transform raw retrievals into structured insights by computing summary statistics, generating interactive visualizations and conducting quantitative model evaluations, thereby accelerating hypothesis testing and decision-making. Many commercial DR agents have implemented analytics features such as charting, table generation and statistical analysis, either locally or via remote services. However, most of these systems have not publicly disclosed technical details of their implementations. In contrast, academic
studies often provide concrete examples: CoSearchAgent integrates SQL-based queries within team communication platforms to run aggregate analyses and produce reports; AutoGLM extracts and analyzes structured datasets directly from table-based web interfaces; and Search-o1’s Reason-in-Documents component refines lengthy retrieved texts before extracting key metrics for downstream evaluation.
Multimodal Processing and Generation. Multimodal processing and generation tools enable DR agents to integrate, analyze and generate heterogeneous data such as text, images, audio and video within a unified reasoning pipeline, thereby enriching their contextual understanding and broadening the range of their outputs. Only a subset of mature commercial and open-source projects, for example Manus, OWL, AutoAgent, AutoGLM, OpenAI, Gemini, Perplexity and Grok DeepSearch, support this capability, whereas most academic prototypes have not implemented it, often due to the high computational cost. As the typical open source studies, OWL and Openmanus extend their pipelines to include interactions with platforms such as GitHub, Notion and Google Maps and to leverage numerical libraries such as Sympy and Excel for combined data analysis and multimodal media processing.
Deep Research Agent with Computer Use. Most recently, the boundaries of DR agents have been progressively expanded through integrating computer-assisted task execution capabilities (i.e., computer use). For example, Zhipu AI introduced AutoGLM Rumination, a RL-based system incorporating self-reflection and iterative refinement mechanisms, which significantly enhances multi-step reasoning and advanced function-calling abilities. Specifically, AutoGLM Rumination autonomously interacts with web environments, executes code, invokes external APIs, and effectively accomplishes sophisticated tasks, including data retrieval, analysis, and structured generation of comprehensive reports. Comparison with OpenAI’s DR: While OpenAI DR primarily focus on intricate reasoning and information retrieval, AutoGLM Rumination exhibits superior autonomy in practical execution. This enhanced autonomy allows it to transform abstract analytical insights into concrete operational tasks, such as automated interactions with web
interfaces and real-time data processing. Moreover, AutoGLM Rumination addresses and resolves limitations inherent in simulated browsing environments by seamlessly integrating advanced reasoning capabilities with authentic browser-based interactions. Therefore, the agent gains reliable access to user-authenticated resources, including platforms such as CNKI, Xiaohongshu, and WeChat official accounts. Such integration significantly elevates the agent’s autonomy and adaptability in both information acquisition and execution of real-world tasks.



Non-parametric continual learning approaches, most notably case-based reasoning (CBR), are currently a mainstream method in LLM-driven agent systems. The CBR-based method enables agents to retrieve, adapt, and reuse structured problem-solving trajectories from an external case bank dynamically. Unlike traditional RAG-based methods, which rely on static databases, CBR facilitates online contextual adaptation and effective task-level generalisation. Such flexibility underscores its potential as a scalable and practical optimization solution for DR agents with complex
architecture. DS-Agent is a pioneering LLM-driven agent that introduced CBR into automated data science workflows, employing approximate online retrieval from a constructed case bank. Similarly, LAM applies CBR techniques to functional test generation, combining trajectory-level retrieval with LLM planning in a modular system design.
Self-evolution paradigms in LLM-driven DR agent systems offer substantial promise for structured reasoning and dynamic retrieval and open new pathways for efficient knowledge reuse and continual learning. Although these methods have not yet achieved widespread attention, they address the high data and computational demands inherent to parameter-based approaches and therefore represent an attractive direction for future research and
practical deployment.



To fully realize the potential of self-evolution in DR agents, future research should expand the self-evolution method
along two complementary directions.
(i) Comprehensive case-based reasoning framework. Case-based reasoning approaches leverage hierarchical experience traces, including planning trajectories and structured tool invocation logs, and employ advanced retrieval and selection mechanisms to enable fine-grained, context-specific adaptation.
(ii) Autonomous workflow evolution promises enhanced efficiency and flexibility. By representing agent workflows as mutable structures such as trees or graphs, researchers can apply evolutionary algorithms or adaptive graph optimization to explore, modify and refine execution plans dynamically. Pursuing both directions in tandem will strengthen the robustness of frameworks and reduce the reliance on data and computation resources.
Conclusion
LLM-driven Deep Research Agents represent an emerging paradigm for automated research support, integrating advanced techniques such as iterative information retrieval, long-form content generation, autonomous planning, and sophisticated tool utilization. In this survey, we systematically reviewed recent advancements in DR agents, categorizing existing methodologies into prompt-based, fine-tuning-based, and reinforcement learning-based approaches from the perspectives of information retrieval and report generation. Non-parametric methods utilize LLMs and carefully
designed prompts to achieve efficient and cost-effective deployment, making them suitable for rapid prototyping. In contrast, fine-tuning and reinforcement learning approaches explicitly optimize model parameters, significantly enhancing the agents’ reasoning and decision-making capabilities.

Brian Wang is a Futurist Thought Leader and a popular Science blogger with 1 million readers per month. His blog Nextbigfuture.com is ranked #1 Science News Blog. It covers many disruptive technology and trends including Space, Robotics, Artificial Intelligence, Medicine, Anti-aging Biotechnology, and Nanotechnology.
Known for identifying cutting edge technologies, he is currently a Co-Founder of a startup and fundraiser for high potential early-stage companies. He is the Head of Research for Allocations for deep technology investments and an Angel Investor at Space Angels.
A frequent speaker at corporations, he has been a TEDx speaker, a Singularity University speaker and guest at numerous interviews for radio and podcasts. He is open to public speaking and advising engagements.










Related Posts



Stay Informed With the Latest & Most Important News
Previous Post
Next Post


Advertisement




