



Now Reading: Microsoft and Chinese Researchers Achieve AI Pre-Training Breakthrough
-
01
Microsoft and Chinese Researchers Achieve AI Pre-Training Breakthrough
Speedy Summary
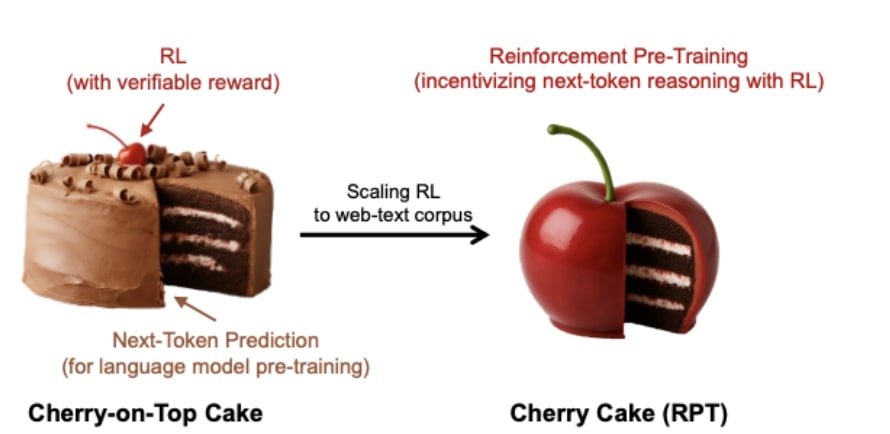
- Reinforcement Pre-Training (RPT): A new method for training Large Language Models (LLMs), reframing token prediction as a reasoning task using reinforcement learning.
- innovative Approach: RPT avoids reliance on expensive human/annotated data, leverages standard text corpora, and mitigates reward hacking issues. It fosters reasoning over memorization.
- Core Functionality:
– Generates reasoning traces before predicting the next token in a sequence.
– Rewards assigned for valid predictions based on the ground-truth continuation.- Multiple rollouts conducted; model trained via on-policy RL.
- Performance Improvements:
– Achieves higher accuracy than traditional pretraining methods across varied token difficulties.
– Matches or exceeds performance of larger models like R1-Qwen-32B on specific benchmarks (e.g., OmniMATH).- Enhances zero-shot reasoning capabilities and supports efficient fine-tuning for RL applications.
- Scaling Advantage: Follows clean power-law scaling with increased compute, showing strong correlation between accuracy improvement and compute investment levels.
- Reasoning Analysis: Promotes structured thinking by employing reflective and inferential patterns during training.
Images from source article:
Indian opinion Analysis
The growth of Reinforcement Pre-Training (RPT) introduces an critically important paradigm shift in how LLMs are trained globally, emphasizing deliberate reasoning rather than rote prediction mechanisms. For India-a country investing strongly in AI-driven innovation-techniques like RPT present significant opportunities to develop scalable AI models without the constraints of expensive human annotation datasets.
The scalability demonstrated by RPT aligns well with India’s large-scale aspirations in data science owing to its abundant access to text corpora through regional languages and local content creation platforms.additionally, fostering deeper inferential reasoning holds practical implications for multilingual AI applications critical to healthcare, education accessibility, and governance efficiency within India.This breakthrough may also enhance collaborations between tech giants like Microsoft or international research partners in integrating more robust foundations into existing projects within India’s academic institutions and private sectors keen on adopting next-generation AI technologies.
read More at Next Big Future










Related Posts
Stay Informed With the Latest & Most Important News
Previous Post
Next Post



Advertisement






{kind=link}
{kind=link}
{kind=link}
{kind=link}